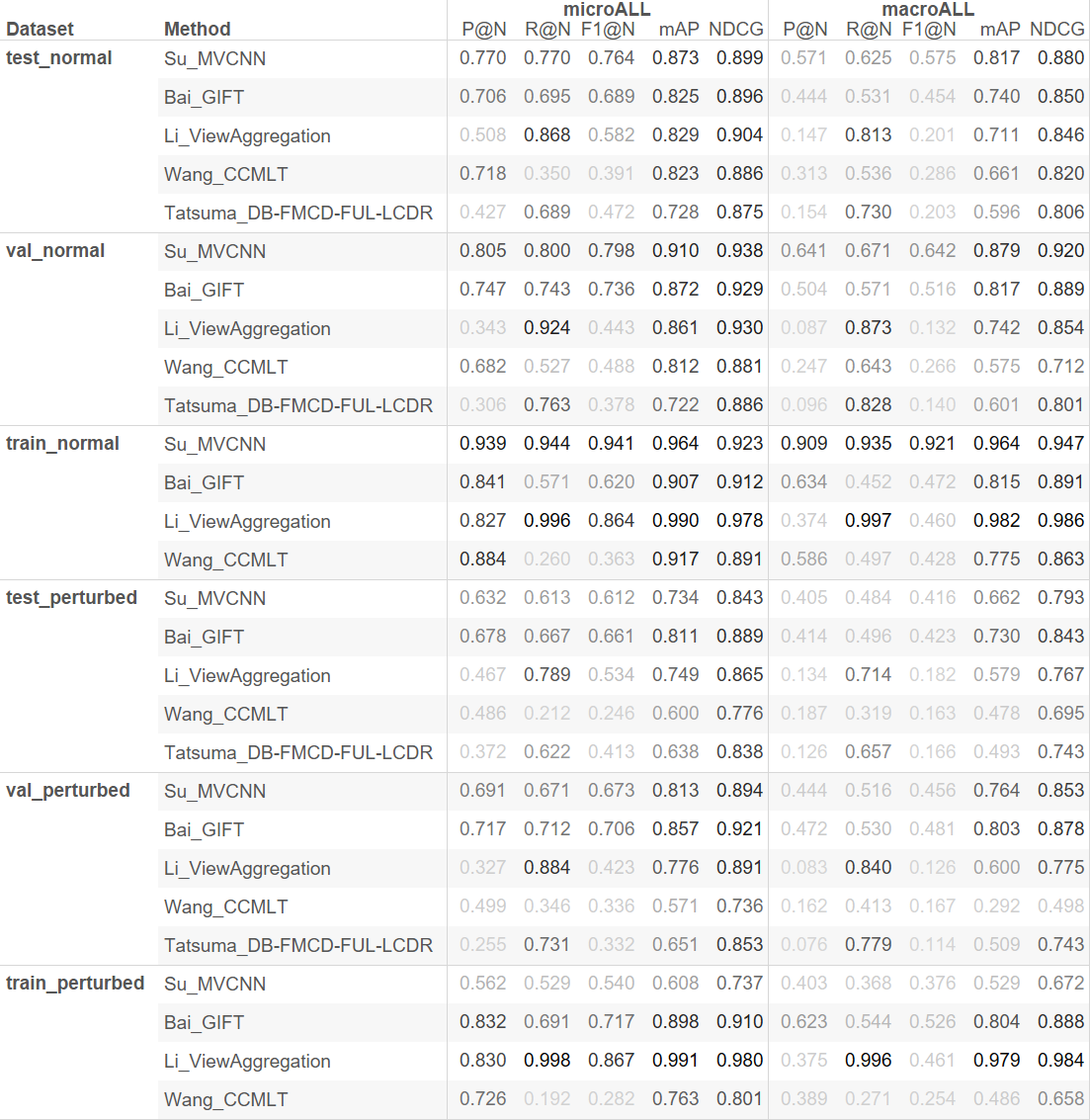
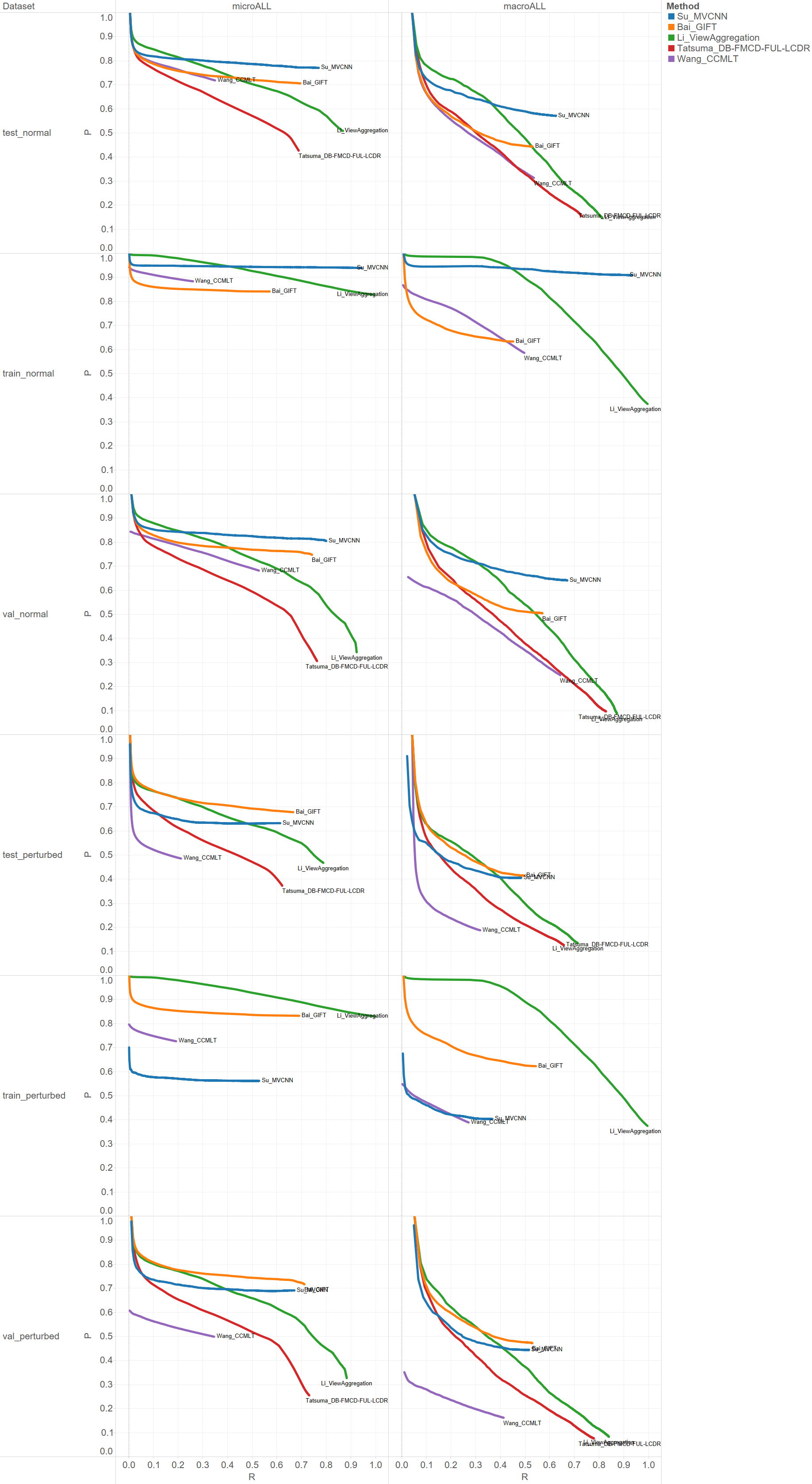
The full track report is now available HERE.
Answers to participant questions, and clarifications about the submission process:
Q1: Which are the query models and the target database models (are they the test models?)
A1: Please treat each test model as a query model and all of the models in the test set (including the model itself) as the target retrieval database. This is consistent with the approach taken in previous years of the competition. Please submit result zip archives for the training, validation and test model sets (both normal and perturbed versions of each). Follow the instructions provided at the competition webpage for packaging and result format. In total you should submit six result sets (train/val/test x normal/perturbed).
Q2: There are two empty model files: train/04090263/model_004004.obj and test/model_039231.obj (and their counterparts in the _perturbed sets). How should they be handled?
A2: Please ignore/discard these models. They will not be considered in the contest.
Q3: I noticed that there are inconsistencies in the models provided in the zip files and the corresponding annotation csv files. What should I do?
A3: In some cases, the zip files contain extra models, and the annotation csv files list models that are not in the zip files. This is due to discrepancies when deduplicating the model data across different synsets. Please ignore any such missing models -- we apologize for any confusion these discrepancies may have caused. Treat the annotation csv files as the canonical lists of models and model synset assignments for the purposes of the contest and evaluation.
Q4: How should the method description be submitted? Is there a template?
A4: Please write a report describing your method and its implementation. Maximum one page with at most two figures (included in page length). No need to include any test result details -- we will be computing the evaluation statistics for all participants. We require both a PDF file and source LaTeX files. Please use the Eurographics 2016 LaTeX template (link). Include the names and affiliations of all members of the team when you submit your method description. For examples, please refer to reports from previous SHREC competitions such as the SHREC 2014 Large Scale Comprehensive 3D Shape Retrieval.
Q5: How and when should the full submission (including method writeup and results) be made?
A5: Package your results as specified in A1, and create your method writeup as specified in A4. Then create a single zip archive with all your files and compute an MD5 checksum for it. Send the MD5 checksum and a download link for your file to shrec2016shapenet@gmail.com by Wednesday March 2nd 11:59PM UTC. We will confirm each submission after it is successfully received. Note that we are extending the submission deadline by a couple of days due to demand. Please note that this is a hard deadline, and we will not accept any submissions after that since we need to run and compile all participant results.
Q6: Where should participants contact the organizers about questions for the fastest response?
A6: Please send email to shrec2016shapenet@gmail.com.